Marginalia: A New Lens for the Internet
It’s nice to meet you, Viktor. I’d love to learn a little about you before we talk about Marginalia, so please introduce yourself. Where are you from and what are your biggest passions?
Thanks!
I’m a Swedish software engineer, dabbler in the humanities and various other things, also a sort of all-round hypertext enthusiast.
What is Marginalia, and what is its purpose?
Marginalia, in a wider sense, is really my presence on the web. It started as a blog, then I began adding other things, things got out of hand, and now it includes an internet search engine which has largely taken over the brand.
The purpose of the search engine is to plumb the depths of the web, to explore all the websites you won’t find on Google or Bing. It puts more emphasis on smaller websites, blogs, stuff written by and for humans.
On some level, it also exists just to show that this stuff exists. Looking at the web through social media, which has a strong vested interest in keeping you on the platform, virtually never surfaces this type of stuff, which, for someone primarily experiencing the web through social media and Google, creates the illusion that outside of those websites, nothing exists except search engine spam.
In one of your earliest blog posts, you said search engines are like lenses for the internet, meaning they’re all good at finding different websites. Where do you think Marginalia excels compared to big tech solutions like Bing and Google? Are there any specific search types you recommend readers try using it for instead?
I think it works best when you’re trying to find something written by a human being. In terms of search capabilities, it’s not that sophisticated, but what it does is it filters the results and removes a lot of spammy and commercial pages. Not that commerce is wrong, but there are other things one might want out of a search query…
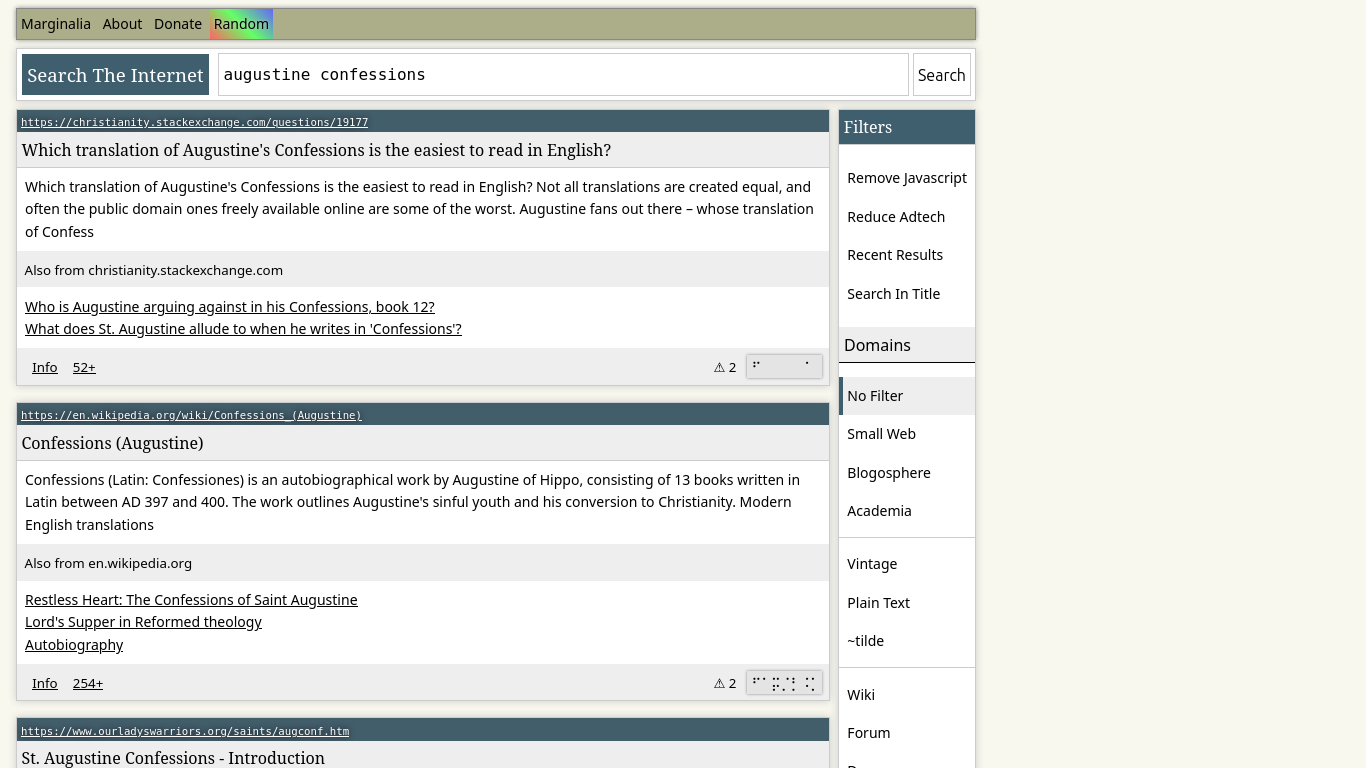
How does Marginalia rank pages? Do you have a set of data points the crawler can assess to decide what makes it to the top of each search result? If so, what are these data points and how accurate have they been with their judgements about website quality?
It looks at many aspects, including more traditional domain ranking approaches, but also other things like inspecting the contents of the documents… both their text and the underlying markup code. In general, it down-ranks documents that have things that are conventionally annoying, like ads, tracking, signs of being written by ChatGPT, and attempts to favor results from websites that are small and non-commercial.
What does it take to run a search engine like Marginalia? I think all of us would like to learn more about the hardware you’re using (and have used in the past) as well as the software stack behind the project.
For the longest time it actually ran on PC hardware out of my living room, but last year, thanks to a grant from the nice people over at FUTO, I’ve been able to move it off to proper enterprise hardware. Since enterprise server hardware makes an incredible racket, I also had to move it out of my apartment and into some guy’s basement. It’s all unabashedly indie.
All the software is custom built in Java. The tricky part about this project is that most off-the-shelf components you might otherwise pick will not be optimized for the sheer scale of an Internet search engine. It means a lot of stuff needs to be custom built from the ground up. Each individual thing that needs to be built isn’t extremely difficult, but there’s just a lot of these components. I’ve worked professionally building software for something like 15 years, and nothing I’ve ever touched comes close in terms of how much breadth it requires.
How do you plan to scale Marginalia as it continues crawling the web? Is there a sustainable way to do this or are all search engines ultimately destined for data centers?
My current goal is to index a billion documents. It’s hovering around 300 million now, probably creeping up to 400 with the next load of crawl data. The new server will definitely be capable of dealing with a billion, and probably then some. The big problem is that while finding a billion documents is easy, finding a billion worthwhile documents is a lot harder.
Marginalia runs on a philosophy of making do with what resources are available. This applies in terms of hardware and manpower and really anything, but it’s unusual in the software space, where you’re more likely to have a bolus of money given to you by some investor and end up in a mad scramble to expand everything all at once. It definitely leaves its mark on the project.
 You can use Viktor’s Website Explorer to find hidden gems from all over the web!
You can use Viktor’s Website Explorer to find hidden gems from all over the web!
As someone who’s very mindful about online anonymity and privacy, it’s great to see options like “Remove Javascript” and “Reduce Adtech” in Marginalia’s search filters. Does Marginalia punish websites for tracking and identifying users, or even for including too many scripts?
The number of script tags is one aspect that the search engine penalizes along with the presence of tracking scripts, though it should be noted it’s a fairly lenient penalty for scripts alone.
In general, it’s an interesting side-effect that websites that have a lot of tracking also tend to be offenders in other ways. You definitely won’t find a spam blog or listicle without tracking scripts.
I always thought anonymity was a key aspect of online life, so I wanted to ask what you think about the global push to link people’s real-life identities to their online activity. During the last two years alone, we saw a coordinated effort to pass EU’s Chat Control, The UK Online Safety Bill, and even The RESTRICT act over in the US.
I mostly think of this as a knock-on effect of larger systemic issues with the web. It’s only because so much of our communication has been corralled onto a relatively small number of centrally controlled platforms that something like Chat Control is even remotely realistic. In a more diverse digital ecosystem, laws like these would be largely unenforceable.
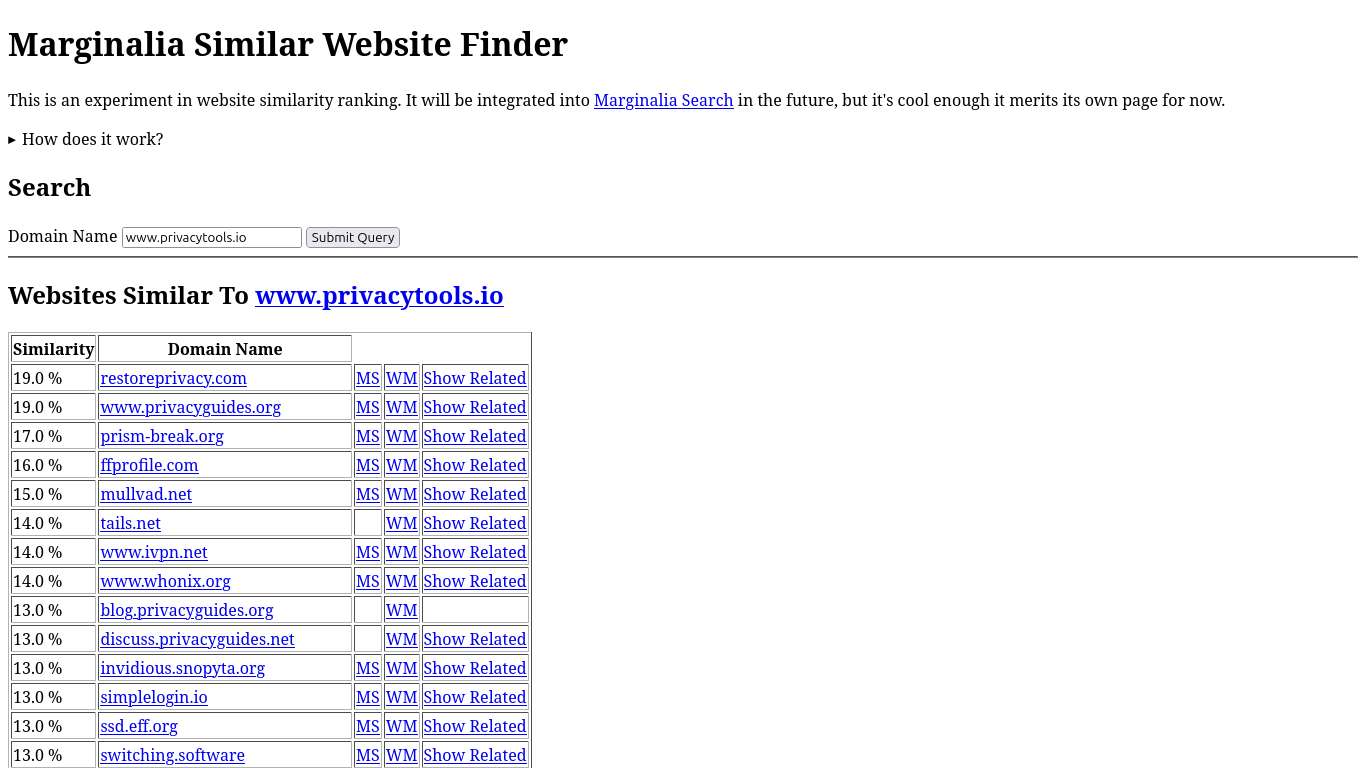 The Similar Website Finder makes it easy to find more of what you like online.
The Similar Website Finder makes it easy to find more of what you like online.
What’s the single biggest problem facing the modern internet today?
Probably the attitude that the institutions we have online are somehow eternal and immutable, and that only big-tech giants are allowed to participate in building the internet; which is just a particular case of people taking it for granted.
If it was a more widespread view among engineers and creative people to see the internet more like a playground where everyone can take part, I think things would be profoundly different.
You’ve used Linux for many years now, so I wanted to ask about your history with it. Which distribution are you using today and what did you use before? Do you have any favorites?
I’m on Gentoo right now, but I’ve been bouncing between Gentoo, Slackware and Debian for the last twenty years or so. I’ve tried a few others, but they’ve always chafed. I think because I want my computer to be like an extension of my will, I really favor distributions that are either very bare-bones or fairly customizable.
Somewhat ironically, I have my desktop environment looking almost exactly like Windows 95, which I think is a marvel of UX with its clear contrasts and intuitive use of spatial metaphors. The fashion with flat design really disagrees with me. I find it confusing and hard to distinguish labels from buttons and so on.
What’s next for Marginalia?
If I knew… This entire project is profoundly experimental in nature, and there’s almost always something new around the corner. Sometimes it’s as though as the search engine writes itself and I’m just around to see what happens.
If you enjoyed this interview, please consider donating to perephoneia.art. Your support helps cover the hosting costs for the website, keeping it free and online for others to discover.